Curiosity and Craft
 Exercising those muscles of grit and resiliency that are essential to improving at our craft
Exercising those muscles of grit and resiliency that are essential to improving at our craft
I’ve been thinking about what drives me to build things. It is curiosity and craftsmanship. Those two things have been consistent throughout my career and life - from LabView as a Physics undergrad, to many different languages and technologies, to Rails web applications, to data pipelines to now LLM-based architectures. Even golf on the driving range as a kid, tinkering with clubs, swing changes. Trying to constantly improve and understand the fundamentals, and then put them to test.
 Early days, decades ago, putting self to the test in tournaments - after work and tinkering with fundamentals and constantly trying to improve
Early days, decades ago, putting self to the test in tournaments - after work and tinkering with fundamentals and constantly trying to improve
“Home AI Pipeline Lab” Setup
I am setting up this AI lab wired into my home network. I just finished configuring a small machine with 96GB RAM and running Proxmox with LXC containers. I am in the process on the weekends of a list of items like setting up an Nginx container, another container with the Cloudflare tunnel, and all the necessary DNS, etc.
 Clean ASRock setup with 96GB RAM ready for Proxmox containers and local AI models
Clean ASRock setup with 96GB RAM ready for Proxmox containers and local AI models
Then add a dedicated DB and Redis containers, an Ollama container or two for serving local models, and have Nginx proxy to my web apps that use them.
Web App and RAG Home Infrastructure
├── nginx-proxy (reverse proxy, SSL)
├── PostgreSQL + Redis (data layer)
├── FastAPI backend (app API)
├── Ollama 70B (free tier recommendations)
└── Claude API integration (premium tier)
General architecture for applications running on my home lab infrastructure
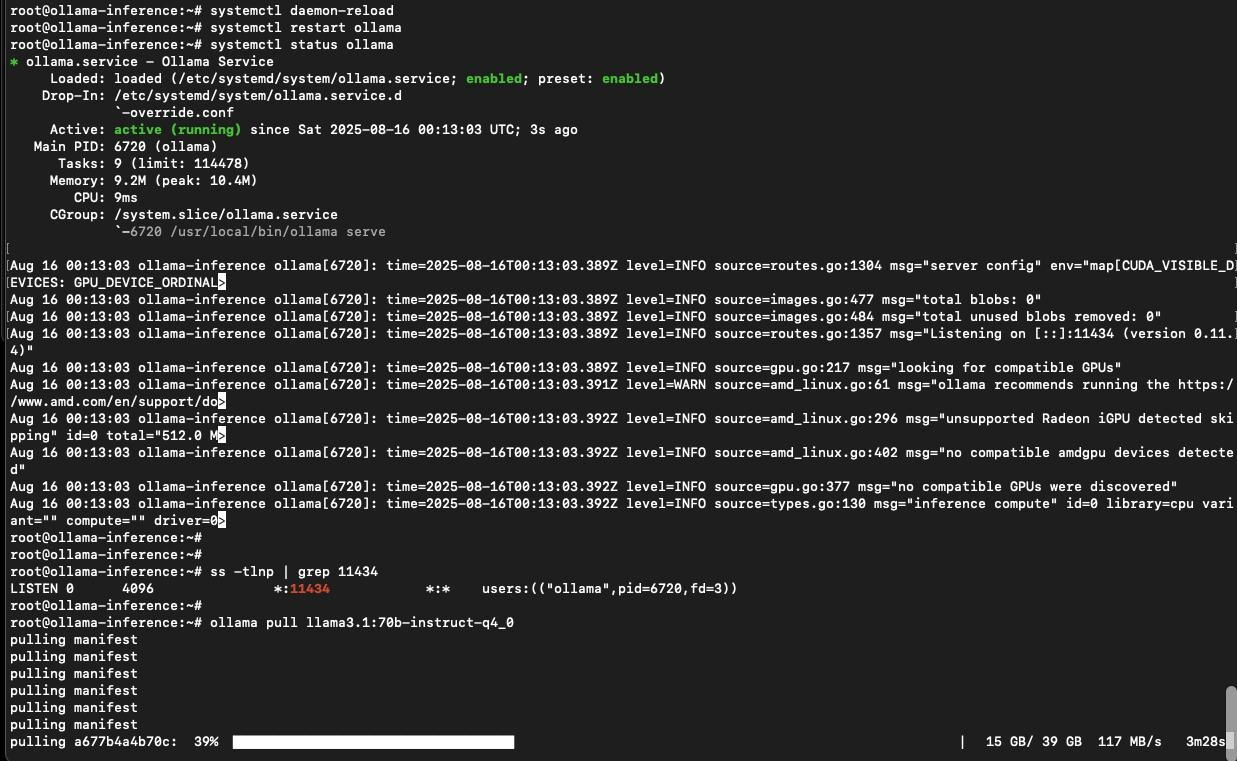 Ollama pulling down language models for local experimentation
Ollama pulling down language models for local experimentation
Once the models are downloaded, I can start testing them with simple API calls:
curl -X POST http://192.168.50.101:11434/api/generate \
-H "Content-Type: application/json" \
-d '{
"model": "llama3.1:70b-instruct-q4_0",
"prompt": "One TV show like Succession:",
"stream": true
}'
Testing the local Llama 3.1 70B model with a simple recommendation query
And here’s the response:
{
"model": "llama3.1:70b-instruct-q4_0",
"created_at": "2025-08-16T00:48:18.073237286Z",
"response": "Great taste! Based on your interest in the complex family dynamics of Succession and the fast-paced, character-driven storytelling of The Bear, I'd like to recommend another TV show that you might enjoy:\n\nBillions\n\nHere's why:\n\n1. Complex characters: Like Succession, Billions features a cast of complex, multi-dimensional characters with rich backstories. You'll find yourself drawn into their world and invested in their struggles.\n2. High-stakes power struggles: The show revolves around the cat-and-mouse game between hedge fund manager Bobby \"Axe\" Axelrod (Damian Lewis) and ruthless U.S. Attorney Chuck Rhoades (Paul Giamatti). This ongoing battle for power and supremacy will remind you of the Roy family's machinations in Succession.\n3. Character-driven storytelling: Like The Bear, Billions focuses on character development and nuanced relationships. You'll witness the intricate web of alliances, rivalries, and personal demons that drive the characters' actions.\n4. Fast-paced, witty dialogue: The show's writing is sharp, clever, and engaging, with a tone that's both humorous and intense. You'll appreciate the quick-witted banter and clever plot twists.\n\nGive Billions a try if you enjoy:\n\n* Character-driven drama\n* Complex power struggles\n* Witty, fast-paced storytelling\n* Morally ambiguous characters\n\nI think you'll find Billions to be an engaging and addictive watch!",
"done": true,
"done_reason": "stop",
"total_duration": 250847368597,
"load_duration": 22127677,
"prompt_eval_count": 30,
"prompt_eval_duration": 82051803,
"context": [128006, 882, 128007, "... (truncated for brevity)"]
}
Local model response demonstrating the LLM inference on home model + hardware
With this setup, I can dive into architecting web applications, RAG pipelines, and exploring the tools and patterns that make AI systems work. Active experimentation beats passive learning - turning ideas into running code rather than keeping them dormant in my head.
The practical reasons are: no API costs, no hosting costs, can experiment freely. But the bigger motivating reason is simpler - I enjoy rolling up my sleeves, getting my hands dirty and making these things work, and also understanding deeply how these systems actually work. I enjoy that process. Specifically, here in 2025, I want to master the fundamentals of designing and building LLM-powered systems, so I can make them operate and perform in ways that scale and solve business problems. In my experiences, the best way to do that is to dive in.
AI pipelines, while different from some of the pipelines I have built over the years, share the fundamentals of good architecture. You still need to think about data flow, error handling, monitoring, scalability and resiliency. Some of the differences I am thinking through now, in general terms: managing context windows for larger RAG applications, routing between different model actions, and dealing with probabilistic outputs instead of deterministic ones.
What I’m Learning Today
- Vector databases - exploring Qdrant for efficient similarity search
- Rerankers - relevance sorters and intent matchers that are quite new to me. A colleague suggested investigating hosted services like Voyage.ai and Cohere for practical reranking in RAG pipelines
- Embedding strategies - techniques for converting text to meaningful vector representations
- RAG architectures - patterns for retrieval-augmented generation systems
- Python frameworks - PydanticAI and LangChain that connect the dots between components
There’s a lot to dig into and learn. Each piece has nuances you only discover by implementing them yourself. It’s an interactive and iterative process for me. The same way I was curious about a linear algebra problem or a calculus problem decades ago, but you you get also use a screwdriver, a keyboard.
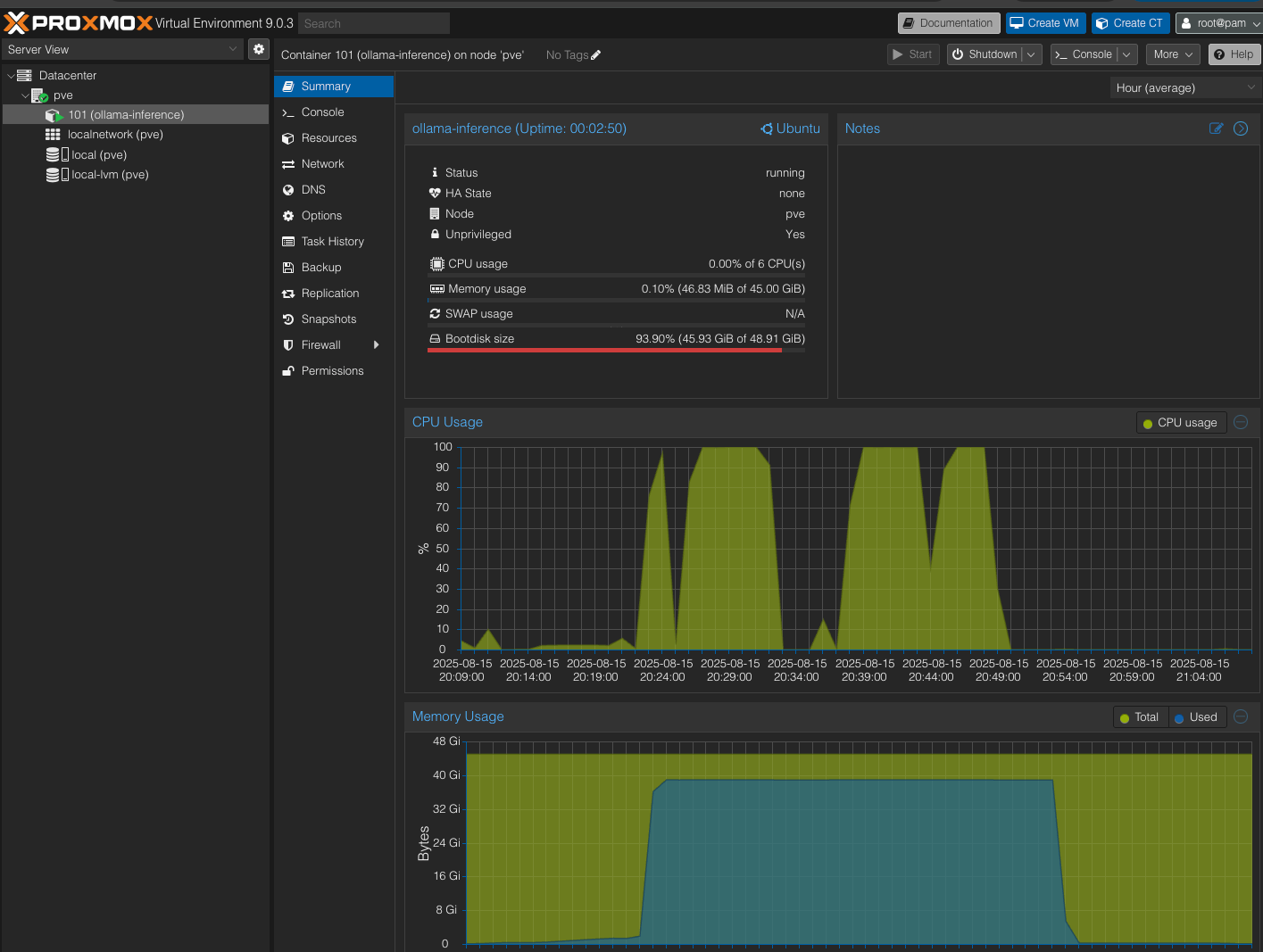 Proxmox container management - monitoring the Ollama inference container with CPU and memory usage
Proxmox container management - monitoring the Ollama inference container with CPU and memory usage
I’m building a couple of Pydantic-AI apps now on the side as a testing ground - one is a recommendation system that uses local models like Llama 70B. Not because the world needs another recommendation engine, but because it gives me a concrete problem to solve with these tools, and I am curious about how I would solve this problem. I also understand already this 70B model is too much for my ASRock machine, but that’s part of the experience (it works, and gives good results, it’s just slowww).
Each project teaches me something specific about AI architecture patterns in practical terms (E.g. Building Conversational Apps with MCP). In that process pushing to solve problems you will get hit with many snags, blockers and hurdles, and the light bulb goes on related to a fundamental you missed in what you were reading, understanding. I encourage you to “just go for it”, and see what you learn — it’s not about the end result or “making a million dollars”, praise and admiration or some external feedback “cookie”. The most sustainable feedback over time, and the stuff that breeds confidence, is in the process of striving for something and overcoming the obstacles to get there. You exercise those muscles of grit and resiliency that are essential to anything we do, but especially software engineering.
Why I Am Curious About RAG Architectures
After decades engaged building and architecting web applications and data pipelines, it feels like a new set of primitives for solving problems. How can I use language models in a way to solve automation problems at scale — these mathematical reasoning engines can understand context very well and generate structured relevant outputs.
The home lab lets me explore this at my own pace. Without cloud bills, API limits, no external dependencies. Just the freedom to try explore and learn.
What’s Next
Going to try and “document” what I learn as I build:
- Giving Proxmox containers a try
- The containers I build and their function
- Pydantic AI framework for building agents
- Temporal for workflows, and lessons learned
- Performance characteristics of different models on this hardware vs the “big boys” like GPT-5 and Claude Opus 4.1
- Architecture decisions for the apps I am building
Build something, you learn from it, you build the next thing better. Keep going and enjoy 🍺
Previous posts