 The LLM acts as the final reasoning layer, turning vector based search results into tailored viewing recommendations.
The LLM acts as the final reasoning layer, turning vector based search results into tailored viewing recommendations.
Where We Left Off
In Part 1, we built the foundation of a movie recommendation RAG pipeline. We took raw user preferences, generated 1024-dimension vector embeddings using bge-large, and stored them in a Qdrant vector database. The result was a semantic search engine that could find similar preferences with accuracy relevant to the user’s interests and mood of the moment.
When we searched for “thoughtful sci-fi tonight,” we got back a ranked list of our own stored preferences:
- (Similarity: 0.679) “I like sci-fi, but with good characters…”
- (Similarity: 0.668) “Something like Arrival but more upbeat”
- (Similarity: 0.666) “More like The Martian less like depressing Black Mirror”
This is the “Retrieval” part of RAG. It’s fast, efficient, and semantically intelligent. But it leaves us with a critical question: How do we turn this retrieved context into actual movie recommendations?
This is where the “Generation” part comes in. The real challenge—and opportunity—is going beyond similarity matching to understand intent: how you want a movie to feel tonight, combined with your historical taste patterns.
In this post, we’ll complete the loop by building a service that feeds these search results to a Large Language Model (LLM) to generate personalized, well-reasoned movie suggestions that meet you in the moment.
Completing the RAG Architecture
Our existing pipeline was fast and effective at retrieval. Now, we’re adding the final reasoning layer. The complete architecture looks like this:
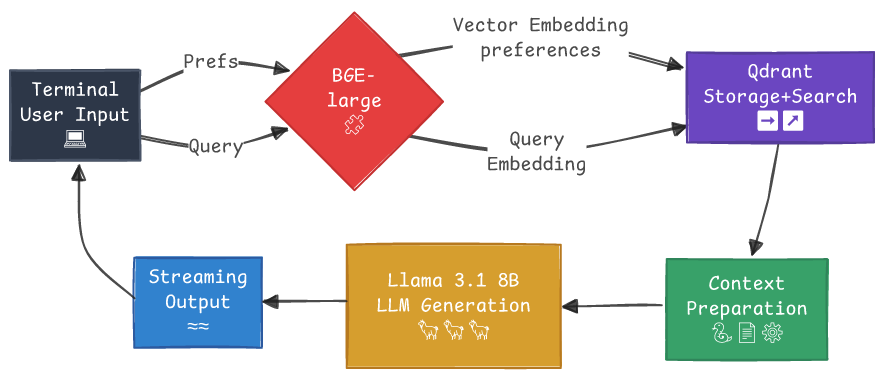 The complete suggest.watch RAG pipeline: User query → Vector embedding → Similarity search → Context preparation → LLM generation with streaming output.
The complete suggest.watch RAG pipeline: User query → Vector embedding → Similarity search → Context preparation → LLM generation with streaming output.
Understanding the Flow
The flow is a classic “fast retrieval, slow generation” pattern. The pattern works like this:
Fast Retrieval Phase:
- Use lightweight, optimized vector search (like Qdrant in this
suggest.watchcase we are describing here, or Pinecone, or Weaviate) - Typically completes in milliseconds to low hundreds of milliseconds
- Focuses on quickly finding the most relevant documents/chunks
- Often uses approximate nearest neighbor search for speed
Slow Generation Phase:
- Takes the retrieved context and feeds it to a large language model
- This is where the computational cost and latency really live
- Can take seconds, especially with larger models
- Does the heavy lifting of understanding context and generating coherent responses
This pattern exists because:
- Vector search is computationally cheap compared to LLM inference
- You can parallelize retrieval across multiple sources quickly
- LLM inference is the bottleneck - it’s expensive and sequential
- It optimizes the overall user experience - you get relevant info fast, then wait for quality generation
Here’s how the complete pipeline works step by step:
User Input → Terminal receives your query (e.g., “thoughtful sci-fi tonight”)
BGE-large (embedding model) - dual purposes:
- Vector Embedding: Converts stored preferences into 1024-dim vectors (happens during setup)
- Query Embedding: Converts your current query into a matching 1024-dim vector
Qdrant Operations → Single database handles both:
- Storage: Houses all your embedded preferences
- Search: Finds semantically similar preferences using cosine similarity
Context Preparation → Formats search results into structured prompt with:
- Your current query
- Top 3 most similar past preferences with similarity scores
LLM Generation →
Llama 3.1 8Bprocesses the context to generate personalized movie recommendations with explanationsStreaming Output → Recommendations flow back to your terminal in real-time, word by word
Complete Loop → You see thoughtful, justified movie suggestions based on both your current mood and historical preferences
Key Architectural Benefits:
- Single BGE-large model handles both preference storage and query processing
- Single Qdrant instance serves dual role as vector database and search engine
- Linear flow from query to recommendations with streaming feedback
- Complete round-trip user experience from input back to terminal display
So our “fast retrieval, slow generation” pattern then looks specifically like this:
- Vector Search (Fast): The user’s query is embedded and sent to Qdrant, which returns a list of semantically similar preferences in milliseconds.
- Context Preparation (Fast): The raw text and metadata from the search results are formatted into a clear, structured prompt for the LLM.
- LLM Generation (Slower): The prompt, rich with user-specific context, is sent to our locally-run Llama 3.1 8B model via Ollama. The LLM then reasons over this context to generate movie recommendations.
For this entire pipeline, I’m using a local AI stack. Both the bge-large embedding model that we explored in Part 1 and the llama3.1:8b generative model are running in the same Ollama container, ensuring privacy and performance with no external API calls.
root@ollama-ai1:~# ollama list
NAME ID SIZE MODIFIED
bge-large:latest b3d71c928059 670 MB ...
llama3.1:8b 46e0c10c039e 4.9 GB ...
The Magic of Streaming: Real-Time Recommendations
Before diving into the code, let’s talk about user experience. Waiting several seconds for a model to generate a response can make an application feel slow or broken. The solution is streaming.
Instead of waiting for the full response, we process it token-by-token as the LLM generates it. This makes the recommendations appear on screen word-by-word, creating a dynamic and engaging experience that feels like the AI is “thinking” through its suggestions in real time.
On my hardware, which is under $1100, and running inference on a Llama 3.1:8b model this ends up being streamed at approximately 12-15 tokens/second to the user:
root@ollama-ai1:~# /usr/local/bin/ollama run llama3.1:8b --verbose
>>> "Based on user preferences for thoughtful sci-fi with good characters, recommend 4 movies with explanations and confidence scores"
Here are four movie recommendations that fit your bill:
**Recommendation 1: Arrival (2016) - Confidence Score: 9/10**
...
total duration: 59.421153368s
load duration: 44.323537ms
prompt eval count: 33 token(s)
prompt eval duration: 617.550141ms
prompt eval rate: 53.45 tokens/s
eval count: 710 token(s)
eval duration: 58.758923041s
eval rate: 12.08 tokens/s
Here’s how we implement streaming in our service using httpx:
# In our LLMService, we use a streaming request to Ollama
async def _call_ollama_chat(self, prompt: str, streaming_callback=None) -> str:
full_response = ""
async with httpx.AsyncClient() as client:
async with client.stream(
"POST",
f"{self.base_url}/api/generate",
json={
"model": self.model,
"prompt": prompt,
"stream": True, # This is the key!
"options": {
"temperature": 0.7,
"top_p": 0.9,
"num_predict": 800,
}
},
timeout=60.0
) as response:
response.raise_for_status()
async for chunk in response.aiter_lines():
if chunk.strip():
data = json.loads(chunk)
if "response" in data:
token = data["response"]
full_response += token
# If a callback is provided, send the token for live display
if streaming_callback:
await streaming_callback(token)
return full_response.strip()
When we call our service, we pass a simple callback function that prints each token to the console. This small change transforms the user experience from a static wait to a live, conversational interaction.
Why Streaming Transforms the Experience:
- Immediate feedback: Users see right away that their query is being processed
- Progressive engagement: Recommendations unfold in real time, building anticipation
- Error resilience: Partial output is available even if not everything completes
- Perceived performance: Feels much faster than waiting for a complete response
Implementation Details:
The streaming callback is then pretty simple:
async def streaming_callback(token):
print(token, end="", flush=True) # Print each token immediately
Implementation considerations (this could be a whole post, but broad strokes for this demo):
- JSON parsing: Skip malformed chunks with
try/except - Timeout protection: 60-second timeout prevents hanging connections
- Termination: Check for
"done": trueto know when generation completes - Memory efficiency: Process tokens as they arrive rather than buffering everything
Building the Recommendation Prompt
The quality of an LLM’s output depends heavily on the quality of its prompt. Our goal is to give the model all the context it needs to act like a movie sommelier. We combine the user’s immediate query with their preference and query history retrieved from our vector database.
def _prepare_context(self, user_query: str, similar_preferences: List[Dict]) -> str:
"""Formats Qdrant search results into a structured context for the LLM."""
context_parts = [
f"User is asking for: '{user_query}'",
"",
"Based on their preference history:",
]
# Add the top 3 most similar preferences from our vector search
for i, pref in enumerate(similar_preferences[:3], 1):
similarity = pref.get('score', 0)
content = pref.get('payload', {}).get('content', 'Unknown preference')
context_parts.append(f"{i}. "{content}" (similarity: {similarity:.3f})")
return "\n".join(context_parts)
def _create_recommendation_prompt(self, context: str, limit: int) -> str:
"""Creates the final prompt instructing the LLM on its task."""
return f"""You are a sophisticated movie recommendation expert. Based on the user's current request and their preference history, recommend {limit} specific movies or TV shows.
{context}
Please recommend {limit} specific titles that match their preferences. For each recommendation, provide:
1. Title and year
2. Brief description (1-2 sentences)
3. Why it matches their preferences (reference their history)
4. Confidence score (0.0-1.0)
Format your response as a numbered list with clear structure."""
This prompt engineering guides the LLM to not only suggest movies but also to explain its reasoning by referencing the user’s own stated preferences, creating a truly personalized and transparent recommendation.
The Complete RAG Pipeline in Action
Now, let’s run the full pipeline! We’ll execute the same search as before, but this time, the retrieved context will be passed to Llama3.1:8b model for generation!
> search thoughtful sci-fi tonight
🔍 Searching for: 'thoughtful sci-fi tonight'
🔢 Generating query embedding with bge-large...
🎯 Searching Qdrant for similar preferences...
🎉 Found 3 similar preferences:
#1 (Similarity: 0.679)
💬 "I like sci-fi, but with good characters, it can't be just about the nerdy sets"
#2 (Similarity: 0.668)
💬 "Something like Arrival but more upbeat"
#3 (Similarity: 0.666)
💬 "More like The Martian less like depressing Black Mirror"
🎬 Generating movie recommendations with Llama 3.1 8B...
Based on the user's preference history, I've curated four thoughtful sci-fi movie recommendations that meet their requirements:
**1.** **"Sunshine" (2007)**
Description: A team of astronauts embarks on a mission to reignite the sun after it begins to die, facing personal struggles and existential questions along the way.
Why it matches their preferences: Like "Arrival," "Sunshine" explores themes of first contact and communication with an alien entity. The movie also has an upbeat tone, balancing action and emotional depth. Additionally, its focus on character development and relationships echoes the user's preference for good characters over nerdy sets.
Confidence score: 0.855
**2.** **"Another Earth" (2011)**
Description: When a duplicate Earth appears in the sky, a young woman discovers that she has an identical twin on the new planet, leading to questions about identity and human connection.
Why it matches their preferences: This film shares similarities with "The Martian" by focusing on character-driven storytelling and exploring complex themes. Its tone is also more upbeat than typical sci-fi fare, making it a suitable match for the user's preference.
Confidence score: 0.832
**3.** **"Passengers" (2016)**
Description: Two passengers on a spaceship wake up 90 years too early and must navigate their feelings for each other while trying to save the ship from destruction.
Why it matches their preferences: This movie combines elements of "Arrival" by exploring first contact and communication, but with a more romantic and upbeat tone. Its focus on character development and relationships also aligns with the user's preference.
Confidence score: 0.819
**4.** **"Europa Report" (2013)**
Description: A team of astronauts embarks on a mission to one of Jupiter's moons, Europa, where they discover signs of life and must confront the implications of this discovery.
Why it matches their preferences: Like "Sunshine," "Europa Report" has an upbeat tone and focuses on character development and relationships. The movie also explores themes of first contact and communication with an alien entity.
Confidence score: 0.805
✅ Recommendations generated successfully!
🤖 Model used: llama3.1:8b
The output streams in, word by word, and about at the pace you can read it. Here’s what the streaming experience looks like in action:
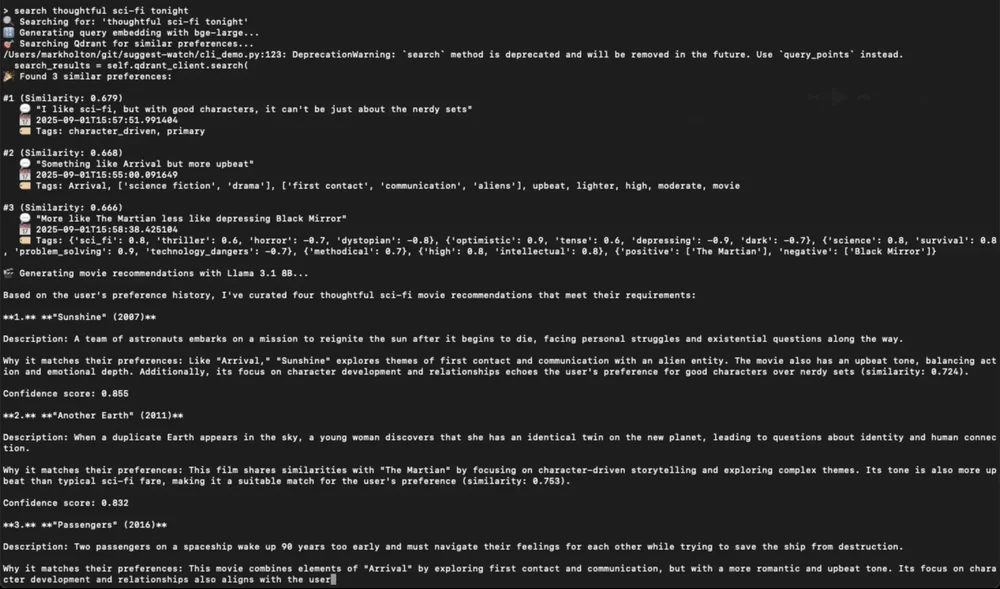
Live streaming output from LLM completing the RAG loop: Recommendations appear progressively as the LLM generates them, creating an engaging real-time experience.
The result is a set of quality, actionable recommendations, each with a clear explanation tying it back to the user’s specific tastes. The LLM successfully synthesized the context: “thoughtful,” “good characters,” “upbeat,” “like The Martian”—to generate a relevant and personalized list.
Fine-Tuning the Generation: Parameter Deep Dive
One area of understanding which can be explored on self-hosted models like our Llama 3.1 setup is direct parameter control. When you use OpenAI’s GPT-4 or Anthropic’s Claude, these companies have pre-configured the inference parameters based on their research and user feedback. You get excellent results, but limited customization.
With local Ollama inference, you control every aspect of generation. Here’s how each parameter matters for movie recommendations:
"options": {
"temperature": 0.7, # Creative but coherent recommendations
"top_p": 0.9, # Diverse vocabulary, avoids weird words
"top_k": 40, # Focused vocabulary selection
"num_predict": 800, # Enough tokens for detailed explanations
}
API Services vs Self-Hosted Parameter Control:
| Parameter | Self-Hosted (Ollama) | OpenAI API | Anthropic API |
|---|---|---|---|
| Temperature | ✅ Full control (0.0-2.0) | ✅ Full range (0.0-2.0) | ✅ Full range (0.0-1.0) |
| Top-p | ✅ Full control | ✅ Available | ✅ Available |
| Top-k | ✅ Full control | ❌ Not available | ❌ Not exposed |
| Max tokens | ✅ Full control | ✅ Available | ✅ Available |
| Custom stopping | ✅ Full control | ✅ Available | ✅ Available |
| Frequency penalty | ✅ Available | ✅ Available | ❌ Not available |
| Presence penalty | ✅ Available | ✅ Available | ❌ Not available |
The main benefit of self-hosted is really the top-k parameter and having no rate limits or costs, rather than broader parameter availability. Top-k is particularly valuable for recommendation tasks where you want to prevent the model from generating rare or inappropriate tokens.
Temperature (0.7): Controls the randomness in the model’s predictions. Higher values (0.8-1.2) generate more diverse/creative text, while lower values (0.2-0.5) stick closer to the most likely completion. Our 0.7 sweet spot gives us creative movie suggestions without going off the rails—too low and you get the same obvious blockbusters every time, too high and you get obscure art films that don’t match the user’s taste.
Top-p (0.9) - Nucleus Sampling: Restricts choices to tokens within a cumulative probability threshold (top 90% likely). It dynamically adjusts the set of possible next tokens based on the model’s confidence, balancing variety and focus. This keeps vocabulary diverse enough for interesting descriptions while avoiding bizarre word choices that would make recommendations feel unnatural.
Top-k (40): Cuts off the sample pool to the 40 most-likely tokens, ensuring the model can’t generate rare/out-of-distribution tokens. This is especially helpful for recommendation tasks needing more determinism—keeping recommendations focused and relevant rather than wandering into random territory.
Num_predict (800): Limits how much the model can generate in response to a prompt. This provides enough tokens for 4 detailed recommendations with explanations, but not so many that the model starts repeating itself or adding irrelevant details.
Additional Parameter Context:
Frequency penalty (0.0-2.0): Reduces repetition by penalizing tokens based on how often they’ve already appeared in the response. Higher values (0.5-1.0) make the model avoid repeating the same words/phrases, preventing responses like “This movie is great because it’s great and has great acting.” Essential for longer responses where natural variety matters.
Presence penalty (0.0-2.0): Encourages topic diversity by penalizing any token that has appeared at least once, regardless of frequency. While frequency penalty targets repetitive words, presence penalty pushes the model to explore new concepts and vocabulary throughout the response, keeping movie recommendations from all sounding the same.
System prompts: Pre-conversation instructions that set the AI’s role, tone, and constraints before user input. Think of it as the difference between “You are a helpful assistant” and “You are a film critic who only recommends movies from the 1980s with practical effects.” Shapes the entire conversation context rather than just individual responses.
Function calling: Allows the model to trigger external tools/APIs during generation rather than just producing text. Instead of hallucinating “The movie has a 7.8 IMDB rating,” the model can actually call the IMDB API to fetch real ratings, or query a database for current streaming availability. Bridges AI responses with real-time data.
Progressive Structure: From Raw Text to Structured APIs
Currently, our system outputs natural language recommendations—good for the CLI and human consumption. But as we move toward a production web application, we’ll want structured data.
We have the flexibility to evolve in stages:
Stage 1 (Current): Raw text output with streaming for immediate CLI value Stage 2 (Next): Pydantic models with JSON schema enforcement for reliable APIs Stage 3 (Future): Rich metadata integration (streaming services, ratings, genres)
# Future: Structured recommendation model
class MovieRecommendation(BaseModel):
title: str
year: int
description: str
reasoning: str
confidence: float
streaming_services: List[str] = []
imdb_rating: Optional[float] = None
This approach lets us build value incrementally—start with working human-readable output, then add machine-readable structure when the use case demands it.
Performance Analysis: Speed vs Intelligence
Our two-stage architecture creates an interesting performance profile:
Vector Search (Qdrant): ~50ms for semantic similarity across thousands of preferences LLM Generation (Llama 3.1): ~5-15 seconds for 4 detailed recommendations
This “fast retrieval, slower generation” pattern is intentional. Vector search gives us instant context relevance, while the LLM provides the reasoning and personalization that makes recommendations compelling. The streaming implementation masks the LLM latency by providing immediate progressive feedback.
The RAG Loop is Complete
Over these two posts, we have built an end-to-end RAG pipeline from scratch:
- 🍿 Semantic Storage: Captured user preferences as 1024-dimensional vectors in Qdrant.
- 🍿 Intelligent Retrieval: Used cosine similarity to find the most relevant preferences for any given query.
- 🍿 Contextual Generation: Fed the retrieved context to a local LLM (
Llama 3.1 8B) to “reason” and generate recommendations. - 🍿 Streaming CLI: Used streaming to provide a real-time, conversational experience. When we build the front end, we will carry this through
RAG architectures give us the speed and precision of vector search, combined with the reasoning and generative power of a large language model. Together, they create a system that understands not just what you like, but why you like it, and can help you discover your next favorite movie.
What’s Next: Building on the Foundation
The current CLI demonstrates the core RAG pipeline, but the architecture sets us up for exciting enhancements:
- Reranking layers for even better recommendation quality
- Web UI a React UI front end for a conversational interface
- Preference learning from user feedback on recommendations - once we have a UI, we can give feedback on what was watched
- Additional metadata (ratings, reviews)
- Multi-modal inputs (movie posters, trailer links?!)
In the next post, I think I will explore how reranking can further improve recommendation quality and handle edge cases where simple similarity isn’t enough.
 Roll credits 🎥🍿 Time to stop surfing through previews and get to enjoying the movie!
Roll credits 🎥🍿 Time to stop surfing through previews and get to enjoying the movie!
References and Further Reading
Part 1 of this series: “Building a Movie Recommendation RAG Pipeline: From User Preferences to Vector Search”
F22 Labs: “What are Temperature, Top_p, and Top_k in AI?”
Codefinity: “Understanding Temperature, Top-k, and Top-p Sampling in Generative Models”